


中国社会科学网讯 4月25日,中国社会科学院民族学与人类学研究所(以下简称“民族所”)民族语言文化行为实验室、中国社会科学院中国少数民族语言研究中心联合主办的“古彝文识别及《西南彝志》全文数据库研究进展交流会”在京举行。本次会议演示了古彝文三种字体的字符识别模型以及《西南彝志》全文检索单机版和网络版数据库。古彝文字符识别和文献数据库建设是国家社科基金重大项目“少数民族语言文献的文本识别技术研究”(24&ZD255)的阶段性成果。

会议现场 主办方/供图
国家民委全国少数民族古籍整理研究室副主任杨硕,民族所副所长(主持所务工作)丁赛,中国社会科学院语言研究所副所长王锋参加会议,民族所民族语言文化行为实验室主任龙从军主持会议。
丁赛提出,民族文字文献信息化、智能化研究是民族所民族语言文化行为实验室建设的重点工作之一,此次会议是古彝文识别和深化研究关键节点,也承载着推动学术进步的重要使命。民族所民族语言文化行为实验研究室在古彝文信息化领域的进展,皆是学界集体智慧的结晶。她特别提到,民族所始终高度重视民族语言的保护与传承工作,在国际与国内双重视角下,借助AI技术赋能古老文明的传承,让民族文化以更鲜活的姿态走进大众视野。她呼吁,期望在国家民委及各界专家的支持下,各方携手推进古彝文文献资源库建设,共同守护民族文化根脉。
龙从军围绕古彝文OCR研究与《西南彝志》全文语料库建设作专题汇报。他提出,当前研究紧密贴合教育部、国家语委、中央网信办印发的《关于加强数字中文建设 推进语言文字信息化发展的意见》,以数字化传承中华语言文化为目标,致力于提升古彝文在数字空间的应用价值与国际影响力。在技术攻坚方面,针对古彝文计算机表示的核心难题,团队与中科院软件所开展深度合作,成功制作16000个字符编码,为古彝文的数字化存储与处理奠定基础。面对彝文输入法复杂、学习难度大的问题,创新性采用国际音标输入古彝文的方法,团队采用“人工录入+技术处理”的双轨模式构建训练数据集,持续优化识别模型。通过不断迭代,逐步解决古彝文标注数据少、识别率低等瓶颈问题,提升了古彝文全文文献库的建设速度。龙从军现场演示了古彝文三个字符模型的效果和《西南彝志》全文数据库功能,他希望与会专家学者下载和使用识别工具,并反馈使用中遇到的问题,课题组将有针对性的解决,不断改进、完善识别模型。

《西南彝志》全文数据库 主办方/供图
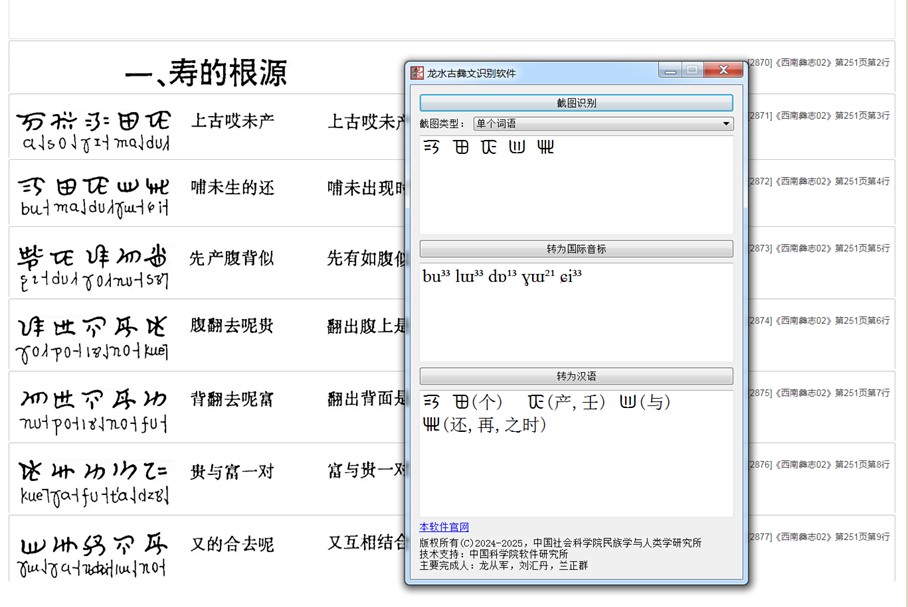
古彝文OCR工具 主办方/供图
课题组在古彝文识别和资源库建设过程中积累的经验也助力民族所民族语言文化行为实验室实现“人机共享结构化数据资源”的短期目标。通过《西南彝志》语料库建设,进一步挖掘古彝文承载的历史文化内涵,推动民族语言文化研究,为阐释多民族交往交流交融的历史脉络、深化中华民族共同体认知研究提供重要支撑。
会议讨论环节,来自中央民族大学、贵州工程应用技术学院、云南民族出版社、西南民族大学、广西彝学学会及民族所的专家学者对本项研究工作建言献策,充分肯定了研究成果的价值,从不同的角度提出一些建议,也表示与民族所科研团队一道共同推动古彝文信息化和深度内容研究的愿望。
王锋提出,随着各民族多文种识别研究不断推进,有望实现文字识别领域的综合性突破,助力相对薄弱的少数民族文字研究在数量与质量上实现双提升,推动民族文字研究进入数字化新阶段。当下的数字化研究依托人工智能技术,不同于传统书籍扫描,为民族文字研究建设、人才培养注入新活力。信息技术可以降低古文字文献的研究难度,激发年轻人的研究兴趣。多语种多文种信息化建设意义重大,其数据库服务范围广泛,涵盖社会历史、宗族文化、中华传统文化等多学科领域,具备知识与文化双重属性,可实现多元信息提取和共享。

与会专家合影 主办方/供图
杨硕对会议进行全面总结。他高度肯定了项目的阶段性成果,通过各方协作,彝文研究实现了重要成果共享,以古彝文文献数据为核心,语言学和文字学作为基础研究,这对构建中华民族共同体史料体系具有关键支撑意义。杨硕着重强调古籍版本研究的重要性,当前古彝文文献存在异体字变体字复杂、版本年代鉴定困难等问题,尤其西南地区文献断代缺失严重,导致难以追溯古彝文规范字演变的过程。他建议数据库建设以雕版印刷文献为准较好,雕版印刷术对文字有一定的规范作用,此类文献是研究古彝文规范的重要依据,应加强对其系统性研究;同时提醒需遵循古籍国标与少数民族古籍定级标准,夯实古籍研究的科学性与规范性基础。杨硕结合自身经历,提出文献解读困境,呼吁加强对古籍背后文化内涵的挖掘与解析。此外,他提出应重视研究成果的传播与转化,推动优质资源融入中华民族史料体系建设,让彝文古籍在更广泛领域发挥价值。
(中国社会科学院民族学与人类学研究所/供稿)













