


摘 要:数字人文须超越工具阶段,其突破点在于如何以计算批评的方式介入更广泛的话语和文化实践中。计算批评是以数据化和计算建模为基础的知识表征和文本诠释过程,是一种全新的文本阐释学,属于广义的文化批评的范畴。它以作为社会实践的观念领域为对象,其前提是可解释的工具,强调模型在思考和推理过程中具有的意义。在“数据→模型→细读→理论→数据→……”的阐释循环中,人文学者从自身的领域知识和细读体验出发,通过巧妙的实验设计论证问题,激活工具的“自反性”,达到破除算法黑箱、发现文本背后的生产逻辑的目的,使“人”的维度在数字时代重放异彩。就现状而言,计算批评或可成为人文学者参与数字人文研究的方法论基础,未来应有更多的量化成果以计算批评的面貌出现。
关键词:计算批评;数字人文;工具性;远读;模型化
作者赵薇,中国社会科学院文学研究所助理研究员(北京100732)。


一、何以走向计算批评
数字人文的兴起已经是一个毋庸置疑的事实。然而纯粹从研究的角度来看,或许还没有一个领域像今日的数字人文这么激情充沛而又毁誉参半,如此混杂、无所不是,却还缺乏必要的共识和规范。从最基础的文献检索,到数据平台的建设开发,或者仅仅是套用软件得出一些似是而非的结论,似乎什么都可以扯上关系,又什么都不是。越来越多的迹象表明,大家只是以数字人文之名,本文为国家社会科学基金重大项目“基于大数据技术的古代文学经典文本分析与研究”(18ZDA238)阶段性成果。在“大帐篷”下寻求暂时性的共同发展,成为一种相对松散的“技术共同体”和跨学科盟友,在研究的根基处,仍然缺乏共同服膺的方法论支撑,也就是麦卡蒂(Willard McCarty)二十年前所说的,人文计算真正应该关心的是那种关于知识的知识,“通用的方法论知识”。而对于更纯粹的人文主义者来说,则是缺少一种自明的正当性,让人仍不免望而却步,心存芥蒂。
在人们的观感中,“数字人文”当然有令人惊奇(刻奇)的一面。它在经学家制作庞大电子索引的故事中露面,成为广为称颂的起源神话;它是由大型科技公司如谷歌图书推出的免费词频检索服务Ngram Viewer;近来还将在TextPAIR算法构造出的中国二十四史“互文性网络”中继续缔造奇观。而在光谱的另一端,“数字人文”是搜搜数据库,用用Zotero,是用开源代码包装兜售的词频软件,是新颖的人文学术营销模式;是中心、项目,学科化和战略合作布局,甚或所有这一切的反面,一套最容易流行的“批判的话术”,无论先锋还是大众,过于工具化还是不够工具化。遗憾的是,对于大多数人文学者,这两种理解模式还都嫌过于简单。
在实践者一方,无论图情档还是人文学者,人们看重的依然是数字人文工具性的一面,或更多将之视为服务型设施来利用。几乎所有开发和建设者(有时是研究兼而有之),无不受着一劳永逸的目的论的驱使,其思路清浅直白。在他们看来,数字人文是一条“问题—解决”的直线路径,从需求的萌生,到工具建造和结果“发现”,其中不必有过多迂回曲折。所谓“数字人文方法论”的引入,构造了稍微复杂一些的框架,如人们反复谈论的,用于描述数字人文活动的七个“原语”。数字人文的堆栈图,特别是它的“中国版”,给出了较为清晰的示意,也让从事各种数字活动的人仿佛都各安其位。然而无论是对“通用”方法的总结,还是堆栈结构,似乎仍不足以构成人文学术所关心的那种“关于方法的方法”,如麦卡蒂所说——若能够作为一个“学术领域”而成立,其基础还在于是否可以通过研究,来追问知识生产的来源——但很明显,当下的从业者却很少,也几乎还未曾关注到这一层。
在关于方法论的思考中,一个尚待突破的方向在于承认数字人文的阐释本质,并通过可操作的批评性环节的介入,来唤醒一种针对工具本身的反思和解释。在这方面,只有少数图情学者,出于理论化和引介的需要,注意到了国外数字人文界对哲学中“反身性”(reflexivity,也译为自反性、反思性)思考的重视,注意到《数字人文:数字时代的知识与批判》一书的作者所提倡的数字思维应向批评开放的要求:“不断反思建构知识过程中所使用的潜在的价值观、方法论、文化背景”。但说归说,在现实中,大部分研究仍未能显示出这方面的意识,更不要说以“问题化”的方式将思考引向工具自身了。应该说,这一局面多少影响了人文知识分子对现阶段数字人文成果的认同,也让他们在某种程度上将有关资源、工具、平台和网络基础设施建设的工作划出了“人文学术领域”。
事实上,在人文主义者看来,“对工具的利用与工具主义常常只有一步之遥”,这更是一种与自身命运倏忽相关的担忧。对他们来说,放弃了超越性的人文学科,在当今高等教育的学科建制受技术和资本双重宰制的形势下,有可能死无葬身之地,因而不得不表现出自然而然的抵拒。早在十多年前,加州大学英语系的Alan Liu就看出文化批评在数字人文中的致命缺席,而将希望留给了“思辨的基础设施”(Critical Infrastructure Studies)和“文化分析”(Culture Analytics)。一个叫作“批判的数字人文研究”(Critical DH Studies)的领域也应运而生,至今热闹非凡。在他看来:
虽然数字人文主义者拥有实用的工具和数据,但除非他们能在文本分析和文化分析之间无缝衔接,否则他们永远无法与莫雷蒂、卡萨诺瓦等人同台竞技。……也许一个充满希望的猜测是,数字人文学科在目前能够对文化批评做出的适当而独特的贡献,是利用数字技术的工具、范式和概念,来帮助重新思考工具性的概念。
有趣的是,十年过去,随着更多人文背景的数字人文学者涌现和文化分析的兴起,我们逐渐看清了弗朗科·莫莱蒂(Franco Moretti)“远读”批评中的诸多局限。其中之一,正是对数字技术根深蒂固的工具性习焉不察的认同。而后续学者的工作,竟也成了以其实绩不断揭除这种工具化的过程。一个简单浅显的例子,是后来者在回顾莫莱蒂对七千部英语小说标题的量化研究时,启用线性回归等更系统的手段,帮助他完成了对描述性统计的超越,从而唤醒了统计学自身的“自反性”,达到了真正意义上的“远读”效果。后来更多的精彩案例也让我们看到,在文本分析和文化分析之间,还有一片叫作“计算批评”的广袤地带。在这里,人文学者以躬身其中的操作,通过解释工具和“通过工具思考”,发展出了更全面的文化批评。这种文化批评的着力点,并不止于目的和对象的政治关切,如更多关于性别、种族、阶级、数字资本主义等主题的加入——这当然有利于纠偏人们对于数字人文价值中立、客观和“去政治化”的印象。但是在我们看来,计算批评的正确性,更在于它能够遵从并运用数字人文自身的形式语言和操作规则,来完成关于工具的反思,这仍然出于一种高度自主的学术要求,而并非横加其上的外在的批判诉求。
二、计算批评的前提:可解释的工具
计算批评的关键在于如何直面人文研究中的工具/模型/算法。直面的前提,是要认识到工具的非透明化,承认数字人文实践中的任何工具,其实质都是一种“解释学的工具”。人们也正是在“利用”和塑造工具的过程中,体会到了解释的物质性,体会到它如何“既是一种实践,又是实践之物”。这里的工具并非海德格尔所说的锤子或铅笔一类随手可得的工具,它不是“透明的”,它比现象本身更倾向于对某种“本体论的规约”(Ontological Commitments)做出先在的选择。正因此,它自身更应时刻引起批评者的注意,否则便有可能被计算结果所携带的算法和审美的复杂性蒙蔽。
必须对这一前提有充分的认识。这是因为,我们总是很容易忽略,我们是通过理解和解释另一套比文本本身更复杂的“工具”(如编码系统、决策程序、推理原则、知识表示)来理解眼前的文本的。“我们正在阅读(在认知诠释学的意义上)一个过程中的人工制品,好像它们就是实际的现象”,这就是为什么哪怕在最简单的词频统计中,隐藏着最复杂的知识表征的合法性问题。与其说是方法论的不相通和互不承认,不如说它们遵守的根本是一套完全不同的文本解释学,或用Unsworth的话说,一套不同的“本体论规约”,一套不同的知识表示方式:在人文计算中,知识表示既指文本表征的各种方式;也指形式化的语法表达,例如启用SGML这样的标记语言,要求元素在指定的层次结构中正确嵌套,其最终目的是实现高效的计算。
“美丽的”(beautiful)这个词在弗吉尼亚·伍尔夫的《达洛维夫人》中出现的次数并不能告诉我们与这部小说主旨有关的任何信息,也不能告诉我们它与其它类型的小说(比如现实主义作品)有何不同。
实际上,这种代表性的危机早就存在了几十年,从20世纪70年代斯坦利·费什对文体学的猛烈抨击,到最近的数字人文论争。在今天,对DH攻击最甚的领域专家,更多是在知识表示层面就无法认同。例如,笪章难(Nan Z. Da)之所以会对计算文学研究发起猛攻,表面上看是由于此前的研究大都建立在词频和向量的降维表示的基础上,往深里说,却仍然是知识表征的问题。在Randal Davis等人的奠基性文章中,知识表征和智能推理相关。笪章难的反感,应该推回到对最基本的语词索引方式的抵牾上。因为语词索引不仅仅只是一种索引方式,它还意味着一套准许其成立的推论(inference),也就是说,你允许它成为整个文本分析的基础,它将报告某些词在文本中的使用频率,或某一长度的词在文本中的使用频率;它将支持某些词重要、某些词不重要的推论……诸如此类,甚至,它还推荐了更多的“推论”出来。换句话说,你相信什么,将决定你终究会采用什么,反之亦然。所以说,质疑一项数字人文研究最“根本”,也是最轻易的做法,就是质疑它的知识基础,这意味着是在反对它的解释学前提。虽然这类做法的出发点并非计算批评,而更像是文化和意识形态的批判。
在数字人文的创世史上,布萨神父编制托马斯·阿奎那著作语词索引的工作之所以被反复提及,也许并不仅仅是因为和T.塔斯曼合作,所采用的打孔编码的自动化流程有多么神奇,而是因为神父的行为,在解释学的链条中也获得了一席之地,重新激活了人们对于阅读的认识。他是如何通过逐词索引的对照表,还原了语词在初始语境和概念系统中的功用,从而再次达成了对“原本”的理解的?在布萨的观念中,也曾有过一套“以意逆志”的思想,建立在对语言结构异于时俗的理解之上,只是今天的人们已经不再去注意这背后的语言学、诠释学传统了。
当然,在今天也很少有人把对事务的认识,仅仅建立在语词索引之上了。然而,无论你是相信“堪靠灯”(concordance)“潜在语义模式”,还是“词嵌入”,抑或什么都不信,我们都应该知道,这里的分歧更是一种诠释学意义上的分歧。“人文学者不能单纯的反对技术,他们的立场本应该更复杂”(苏真)。令他们起疑的应该是将技术用于某种特定阐释模式的任意行为,一种不为人知(或理所当然)地建立起意义关联的方式。这种未加审思的关联,像符号“自然化”的过程一样,理应得到分析和再检验。这是因为,所有事无巨细的人文阐释,都是和算法环环相扣的;所有的阐释和应用无不是关于算法的阐释应用,不理解内置的模型和算法,就无法在计算批评的过程中真正地运用工具,更谈不上有针对性地根据模型来设计实验、研究问题了。因而,也正是在这个意义上,我们很难未加证明地便相信,一种仅仅基于关键词计算出来的“情绪曲线”,便代表了小说家、诗人的情感走向;在不经任何统计检验的情况下,就可以言之凿凿地用于一系列批评生发。在一篇批评文章中,作者使用名叫“一叶故事荟”的“大数据文本分析软件”,生成了几个“自杀诗人”早、中、晚期创作的“情绪曲线”,认为这些曲线很典型地代表了自杀者的“情绪模式”。又仅凭“我”“你”“他”“黑暗”“黄昏”等词汇出现频率的细微“变化”,试图说明其与诗人“死念”之间的必然关系。可以说诸如此类的“数字人文”研究问题多多:如样本选择的人为偏差(并没有同时考察非自杀诗人的情绪曲线和高频词分布);软件算法和预处理步骤一无所知(读者凭什么要相信该软件,所谓情感计算的原理是什么,为什么不能公开算法?在计算词频的时候都移除了哪些“停用词”?);不具备起码的检验意识(不做显著性和相关性检验,很难说明“变化”确实发生了);等等。此外,文章也未能对任何图表做出坦诚而令人信服的解释,令人怀疑作者自己是否真的知晓软件所启用的算法是什么。图表在作者手里,成为任其发挥的画符。这类情况在“文学数字人文研究”中并不少见,不一而足。可以说,在反对工具的透明化这一点上,大部分学科的数字人文学者已达成了共识。人们应该敢于反对“装神弄鬼”,包括利用算法不可知的封装软件进行解释,哪怕是用于拆解另一个AI的“批评”行为,也不过是表面上的反其道而行之,在本质上很难说不会造成“二次蒙蔽”之实。在这个意义上,计算批评学者建议人文学者养成更高的统计素养,并且能够批判性地运用之,而非仅仅停留在揭露数据的滥用上。
同样的道理,在大部分非工程领域,在某种“计算阐释学”还没有发展起来的当下,数字技术也并非越“智能”越好。深度学习固然极大提高了预测模型的准确性,但是众所周知,在一些追求自动化效果的文本挖掘任务中,大模型的更新换代越来越快,内部的算法却变得难以理解,可解释性下降,造成了过程的“黑箱”。事实上,就人文学科而言,我们未必拥有那么多要解决的科学难题,相反,我们需要的是待解释的,可以被解释的技术和操作,可用于进一步的概念化,来和人文学术问题对接;我们不是拿文本和文化去解释技术,而是要反过来“利用”技术呈现人的思考过程和思辨能力。更进一步说,我们需要在这一过程中去追问某种阐释的公共基础是什么,或者说究竟是哪种具体的知识、文化和经验,赋予了工具以解释的魔力。从另一方面看,人们辛劳地建造了大量庞大的图谱,然而这些图谱并不是为了代替人文学者的工作,退一步说,如果人们在基本的编码层面无法认同它,那么这种技术仍然很难具有公共效力。很显然,无论中西方,技术的进步都是惊人的,然而,那种善于理解工具自身的文化还远远没有培育起来。
今天,通过Melissa等人的编著,我们得以再次重温人文计算学者振聋发聩的声音:人文计算,某种意义上也是今天的数字人文,它绝不只是以数字方式完成人文学科这么简单,计算机也不仅仅是一种工具。至少,在人文计算中,计算机被用作人文数据建模,同时,也将对我们对它的理解进行建模,而这一活动,“完全不同于使用计算机建模打字机,或电话,或留声机,或它可以成为的任何其他东西”,其中原因,乃在于它在参与人的创造和阐释这样一种别具一格的工作。这其中高扬的人文主义,至今让人感慨。也正是在这一意义上,Melissa强调,人文计算主义者的宣言,在今天可以说比2002年首次发表时更加重要,“因为它对数字人文学科是否只是以数字方式完成的人文学科,以及计算机是否只是一种工具,这一长期存在的问题提供了独特的视角”。
三、计算批评的关键:通过模型来思考
让工具不仅仅只是工具的办法正在于:亲手建造它,通过工具来思考,继而思考其自身,而不是将它作为直达目的的手段。这是因为,“建造”是为了帮助人文主义者更好思考和阐释,而非把模型直接等同于现实,陷入一种“得筌忘鱼”的境地。“当你通过它思考时,你正在思考它”,“思考”这个动作发生的时候,便撕开了Representation的面纱。在计算批评中,能否通过建模的过程来思考和推理,将成为至关重要的一步,这决定了你手头上的工具是否会被点铁成金,化为一副“心灵的望远镜”。
严格说来,任何真正的数字人文研究,必不可少的一个环节就是“模型化”。在拉姆塞的“On Building”(《论建造》)等文章中,是否从事这种建造工作,甚至成为区分数字人文的标准。“一个人必须在心中有某种模型,以便制作工具。构建工具是一种将这些想法正式化为算法的行为”。在Ted Underwood等人看来,以建模为方法已经成为计算批评的根本,这是近十年来,莫莱蒂之后的人文学者围绕着统计模型的概念,一直在发展的一种严密的方法论。然而,人文学中建模的目的并不同于科学建模。在科学中,建模的目的是成功预测,在人文学科中,更是为了理解现象的特殊性,它欢迎富有成效的失败。
人文主义者建模是为了让模型成为推理和论证的关键一环,而不仅是塑造一个AI,一个忠实的模拟物的世界。“如果我们能够开发出一个可以预测任何作品或回答任何问题的文学模型,我们会感到失望;那么阅读的意义又何在?相反,我们致力于追求超越每一种模式的不可言喻的东西”。正是通过利用模型,通过精妙的操作和实验设计,甚至误差项的设置,这些“不可言喻”的事物才得以显露出来。某种程度上,这也是对模型“自然化”过程的批评和揭示,是人文学者的自觉行为。所以,必须时刻将建模时的设计与选择变得可见。建模是一种中介性行为,必须将人们的注意引向对于知识的建构性的关注上。模型的关键并不在于代表性的程度,而在于它如何促成了“推理”:
重要的问题是一个模型在多大程度上允许一个特定的用户做出有效的推论,而不是一个模型在多大程度上看起来像它声称要代表的世界。
也就是说,如果你推崇计算机,那是因为计算机成为你思考的工具,而不是相反。在文类研究中,聚类和分类模型的采用,并不仅仅是为了可以分得多好,多么准确,很多时候更是为了测试和确证,进一步得出文体研究所关心的结论。这方面的一些例子,来自对机器学习的应用。
现如今,基于统计的机器学习只是一种初级阶段的建模策略了,它自动而且“智能”,可以通过大量“训练”,在未识别的数据集中习得一些“潜在模式”,从而将这些数据按人类的经验范畴来归类,也就是说,重点是对缺乏定义、只能从例子中推断出来的分类实践进行建模。我们当然可以利用这一过程,像分拣垃圾邮件一样,从事一种图书分类的工作。但是如果我们直接把这种分类手段与文学的类别研究对接,将很可能行不通。因为很快便会发现,正所谓“设文之体有常”而“变文之数无方”,不仅在各种文学体裁之间很难划出一条截然的界线,而且文类自身也会随时势而变,我们如果正面出击,则很可能如愚夫般碰壁。但是,如果反其道而行之,在承认文体边界相对模糊和文类观念变动不居的前提下,将问题转化为,是什么让一些人将某种文本知觉为某个类别;或者,转而去考察某种文类体式的概念到底有多大“稳定性”和“代表性”,这样的问题则显得有意义得多。在文类研究中,一种思路便是将机器学习的建模和传统的细读结合,借助算法来“发现”某种文体模式的“本质”特征,当这种“本质”恰恰迎合了我们的批评诉求,则有助于完成批评的“实证过程”。因而明智的做法,并不是像莫莱蒂的欧洲小说兴起的研究那样,对四十四种英国小说亚文类直接做聚类可视化,呈现出一种二百年间此消彼长的兴替过程,一种“本该如此”的效果(同时也是很难证实的结论),而是要对文类“视角”和文类观念本身建模。这其实也是一些研究者们正在做的事情。
在这个路径下,一个反复提及的例子是关于英语俳句的研究。我们知道,美国现代主义时期的俳句写作,和后来的意象派运动发生了重叠,本质上还是东方主义色彩中的诗歌,那么,怎么把这种隐蔽的观念揭示出来?研究者们设计了一个实验,抓住了历史上的俳句概念争讼不清的特点,利用被同时期的批评家明确地指认为“俳句”和“非俳句”的文本集,让机器去学习这些语料,训练出一个拟合度较好的分类器,再把模型的参数稍微调宽松一些,“钓出”那些被算法误判的“潜在俳句”。继而通过细读,去发现是哪些措辞和带有东方情调的意象“诱使”机器做出了归类。如此,便可以借助于俳句的统计模型,从一个“散落在数十家期刊的上百首诗歌”的水平上,将人们心目中的“俳句本体观”识别出来,去认清俳句(及其模仿运动)在构成更广泛的东方主义文化和现代主义历史中的重要角色,进而对其背后的生产逻辑进行精细化的批评剖析了。
值得一提的是,这个实验的设计,建立在研究者对文本表示模型的正确选择和对朴素贝叶斯算法的细致理解之上,而所有的策略又都是根据对象特点量身定制的。一方面,俳句以词语意象为表意单位,和同样以词汇为基础的词包模型正相匹配。也就是说,研究特定时期的英语俳句,意味着表示模型可以很简单,而不必顾忌“词序”或语法。试想如果对象不是意象派诗歌,而是小说,仅仅基于词频的分析就很难站住脚。另一方面,选择基于概率来做归类的朴素贝叶斯算法,对语义和低频词更敏感,这无疑有利于研究者相当明确的“挖掘”目的的实现。最后,问题的特殊性,某种文化批评的初衷,决定了分析的目标将是意指相对固化的词汇语象(如东方语境中的“池塘”“雪”“雨铃”“芦苇”等),这就不涉及更复杂的表意过程的学习。否则便要将上下文也考虑进来,要启用更“高级”的深度学习模型(如神经网络模型RNN,CNN,甚至Transformer)。而若真如此,便也可能背离人文学者的初衷,因为无监督的模型,内部的计算程序很难知晓,也就无法通过“反操作”来和算法对话,以“短兵相接”的方式破解算法黑箱了。可以说,这样的研究加深了人们对于某个时期英语俳句文化的理解,建立在模型最大的特点——可调节和可操控性上。通过亲自构造和调节模型,人们看到的是智识的闪光,而不再是手段—目的式的简单思维。
在文类研究中,同样熟练利用模型的可调节性和参数化进行推理,且能够更新文学认识的另一种做法,是用机器学习来考察文类观念的“内聚性”和“连贯性”。例如,用已有标签的文本作训练集,测试模型对剩余文本的分类准确性,加入不同变量后,则可以推论出不同时期、地域、群类范围内,分类标签的一致性和连贯性。Underwood等人曾以此证明了从稍长一些时段来看,科幻小说的观念具有更强的“稳定性”。这类被称之为“视角建模”的策略,可以提供更灵活的描述办法,仍然是以承认算法在被创造时就编码了一系列主观选择为前提的。其精妙之处,正在于用机器暂时性地构造“人类视角”,来再现这一绝非客观的认识过程。以此为切口,探讨形式主义和历史主义文类理论各自的偏颇之处,提出更符合文类观念形塑的“模型”,为验证命题服务。
从这些例子里,我们看到Rockwell 和Sinclair等人所说的“通过模型来思考”的人文意义所在。这种思考必然是一种计算诠释的过程。在计算批评学者手里,模型成为重建历史观念和进一步推出结论的工具。通过调节“观念模型”的输入,或构造不同的模型,便可以得出不同的输出,以验证关于文类持存范围的假设;或通过细读其输出“错误”,反过来了解不同人文视角间的差异,达成一种全新的理论思考。在此,“错误”或“误差”提供了系统化地探究问题的契机,也打开了阐释的罅隙。必须时刻清醒:“历史学家需要做的,正是捕捉隐含在一组特定的人类选择中的不公平的、定义不明确的假设。文学史研究者们知道,他们想要重建的实践并不是中立或客观的……当读者要把一本书归类为科幻小说或奇幻文学时,作者的性别可能会起作用”。而事实上,起作用的因素还有很多,时代、民族、阶级、地理等。更多时候,我们的对象是社会实践在观念领域的投射,是人的经验问题。我们永远都是在一个解释学的框架内行事,而不是幻想以“高科技”的手段去捕获客观实存的现实本身。因而,这样一块充满了比较和相对主义、充满各种阐释可能的天地,本来就应该是人文学者的自留地,在历史遗留问题上还大有可施展的空间,而并不一定要交由自然科学来拓展。退一步说,在今天,即便自然科学家也在使用统计数据来证实研究者的主观假设或先验,这一已被社会科学接纳的做法,应对人文学者有启发,我们当然也可以使用统计模型来表征和反思,甚至解构。在现实中我们终会发现,若索性放弃将数字技术作为抵达真理的工具这一执念,研究将更易出彩。
四、回归方法论
一旦数字工具涉足人文领域,它就既不是望远镜,也非显微镜,而是一块独特的、可以远近拉动(scalable)的诠释学透镜,一种用于具体阐释的比例尺工具。一句话,你看到什么样的景象,取决于你把透镜调节成什么样的观察尺度。然而,无论是远距离的统计阅读,还是近距离的细读,强调观察途径的主观性,并不意味着要放弃系统性的方法,更不是在面对描述性统计的结果时,可以想怎么说就怎么说,要探讨这其中的一定之规,有必要先厘清几个问题。
首先,对人文学者来说,可解释的模型究竟是什么?如果说传统人文学者直接从文献资料的观察、理解中抽绎出理论,那么模型在计算批评中扮演何种角色?模型和算法都是数字工具,最大的特点在于可为人所操控,可以将人们抽象的思考过程外显出来,形成新的理解和命题。所以一个直观的讲法,是从和理论的关系上来理解模型。Ramsay和Rockwell在2012年便展开了关于模型如何被认作一种理论透镜的对话。2016年,在关于意识流全球传播的研究中,研究者对上千本英语意识流小说进行风格建模,再用几乎相同的分类器,对半边缘和边缘地区的小说做测试,经过并不复杂的三道实验和二步推论,不仅验证了莫莱蒂的世界文学猜想,还将世界文学的形态从“波浪”修正为一种可测量的“湍流”模式。也许在人们看来,这个研究并未得出什么颠覆性的结论,唯一的“技术结晶”也仅仅体现为一个多特征的跨语言分类器。但正是借助这个模型,可以凭借误差参数的调节,捕捉到模型无法解释的、不可言喻的东西,这恰恰表现为文学形式在跨文化旅行中“异质同构”的结构本身。经过这一“自反性”的步骤,统计模型才真正成为麦卡蒂所期望的探索不确定性的理论透镜。可以说,这类探索将可操作性引入文学理论研究的激进方式,是于无声处听风雷的。而正是在这一过程中,模型成为理论化的雏形,作为从“数据资料”到“理论抽象”的中间环节,被人文学者生产了出来。
也许,在与量化人文研究有广泛关联的计算社会科学看来,仅仅一次性生产出新的“命题”,仍然是无法升华成“理论”的,还需要在更大范围样本上进一步验证,也就是进行所谓的模型检验。同样,在计算批评学者手里,批评不是套用现成工具,更不能止步于以你的样本来论证模型的合理性。如果你用中国和东亚的文本,仅仅证明了一套用以印证西方崇高理论的算法的合理性,你会遭到质疑。相反,如果你用更多的数据和办法,证明了模型的局限性,修正了模型,促成了新理论,这会是一轮正确的阐释学循环。接下来,或需要将更大规模的材料数据化,开始下一轮数据—模型—理论(化)的循环,只不过进来的数据并非越大越好。到底什么样的选择是合适的,是近年来计算社会科学或者说社会计算一直在考虑的问题。
在Journal of Social Computing的主编寄语中,社会计算的方法论被明确解释为“数据—模型—理论”的三角结构(如下图)。罗家德认为好的研究一定是在不断地挖掘资料,设计实验,解释结果,对话理论,再拟合资料,再调整模型,结果或可提升为新理论——只有如此,模型才会变得“智能”,理论也会越来越精微。
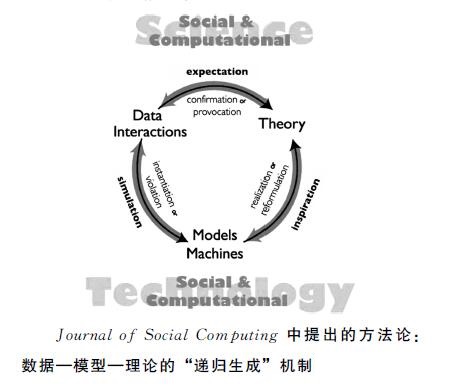
其次,对于大多数人文研究特别是文学研究来说,或许人们更关心的是,细读的位置在哪里?审美主义者捍卫的那种文学性似乎已经没有存身之地了?我们需要灵感、直觉、心有戚戚的共情,需要文学修养,需要那种数字素养换不来的宝贵的审美体验,以及必备的知识积累和问题意识。事实上,除了在审美感兴阶段,为获得一种“批评前反应”和独特的问题所做的文本阅读,在资料收集、数据编码、实验设计和特征建模,乃至推论的最终得出等方面,计算批评对感受性、洞察力和领域知识的要求都远远高于传统研究,这尤其表现在模型检验和理论对话的环节。在此,细读或者说精读常常发挥了至关重要的作用。
上述例子中,每一个个案都是通过在关键处引入单一段落的细读,提供了更好的粒度和证据,才将研究推进到新的层面的。也就是说,当模型将我们想看到的东西呈现出来,依然要通过细察数据来解释和评估结果,以人的洞察力来发现问题,指引方向。在《文学模式识别》中,为了初步确定是什么特征让某些诗那么地“像俳句”,研究者必须调出由单个归类测试产生的概率列表样本,去弄明白词汇层面的“俳句性”究竟是什么。在《湍流》和斯坦福文学实验室关于小说句法的研究中,算法模型轻而易举地将离群值查找出来,然而如何合理地解释那些出人意料的段落和文本?此时仍需要调动全部的文学经验,方有可能获得有意义的答案,为进一步的“模型修补”指明道路。换一个角度说,返回细读,这个动作让人们准确地看到了算法的失败,知晓机器是如何对复义和含混进行“强制消歧”的,也让人们得以“准确地说出我们如何知道我们自以为知道的东西”(麦卡蒂)。当细读体验和算法直接交手,注意力被自然而然地引向知识的建构过程,引向关于知识的知识。明确了这一点就会发现,真正意义上的计算批评无不受破解算法的好奇心驱使,在一些无监督的实验中,仍然可以看到这种可贵的努力。和细读的动机如出一辙,这种努力让模型的引入不至于成为“炼丹术”,变成某种公然的套用行为。
在此,也许不难概括出一套“方法论”的框架来,建立在计算社会科学的基础上,又加入了人文成之为人文的要素。也许,我们不妨尝试把三角结构拉伸为“数据→模型→细读→理论→数据→……”,一种以细读为关键节点,在探索性研究和验证性研究间不断循环递进的结构。
对计算社会科学来说,回归方法论在今天之所以意义重大,也是因为大数据的加入,为传统的假设—验证的实证范式带来了压力和困惑。莫莱蒂断言,“大数据”让人们对理论的好奇心下降,数字人文是一个“非理论”的领域,而且将永远处于一种“探索的狂热情绪中”。但是在人文学科内部,有必要把理论的式微归咎于大数据吗?莫莱蒂这么说,很可能因为他自己的研究便不能令人满意,虽有强烈的理论兴趣,但在面对数据时却时常显得束手无策,他看不到出路。而这也未尝不是多数人文学者的常态,他们还没有接受起码的实证方法的训练(包括实验设计和测量),还根本就未理解假设—验证的操作框架,却想一步跨入大数据、大运算、大模型。
这个问题说到底,也是由于未能处理好探索性研究和验证性研究之间的关系。按计算社会学家的说法,这类问题自20世纪60年代起,在统计和数据科学中就一直争论不断,只不过“大数据”的风口来临,让问题更为紧迫。于是在现实中,我们看到太多平庸而令人沮丧的个案,它们的数据规模未必有多大,单纯靠数据和技术驱动却难以形成合理的“解释闭环”。所以现状是,一方面图情信息技术日新月异,但在现阶段似乎更侧重资源的建设、存储和共享;另一方面人文学者也开始追求自动化的工具和越来越高超的表征,可落实到具体个案的设计和论证上,却常常是十八般武艺都使上了,到头来仍然既没形成明晰的问题,也缺乏引人入胜的思路,更不用说给人印象深刻的结论了。
数字人文并非没有理论和方法。在这方面,人文学者或许应多多借鉴计算社会科学的经验,考虑如何将数据驱动的探索性过程,和由实验设计来担纲的验证性思路结合起来,让研究从数据预处理阶段开始,就受到具体而微的问题意识的召唤,而非仅靠技术的可能性来单向牵引;注意根据问题来设计专门的实验,建立模型,检验结果;调动自身的批评性经验解释结果,检验模型,与算法和既有理论对话,从而验证假设,抑或调整模型,形成更明确、更有价值的“问题”,再补充进新的数据,完成多轮论证,直至最终推出满意的结果。从这个角度来说,与追求宏大知识表征的基础设施建设不同,在诸多细小的人文问题上,计算批评提倡“从小处入手”(think small),它为数字人文提供了一种从内部突破、重返人文本源的可能。
本文注释内容略
原文责任编辑:马征
扫码在手机上查看












